





Slik gjør du industriell data egnet til ditt bruk
Det kan virke som de fleste produksjonsbedrifter drukner i industriell data, men allikevel strever med å utnytte mulighetene dette gir. Vi gir deg en praktisk guide i syv steg.

Et moderne industrianlegg kan produsere en terrabyte industriell data hver dag. Med en bølge av ny teknologi innen kunstig intelligens og maskinlæring, samt dashbord med sanntidsdata, står vi overfor store muligheter til optimalisert produksjon. Uplanlagt vedlikehold av produksjonsutstyr bør høre fortiden til.
Allikevel, i 2021, er ikke dette tilfellet. Tilgang til store mengder industriell data er ikke synonymt med at det benyttes til noe nyttig. Industridata kommer ubehandlet, og må prosesseres før man kan trekke ut den sanne verdien. Verktøyene som brukes til dette må i tillegg kunne håndtere en utvidelse av fabrikkanlegget.
Så hvordan gjøre industriell data egnet til ditt bruk? Med nevnte utfordringer i bakhodet presenterer vi en steg-for-steg guide.
Steg 1: Start med use case
Prosjekter innen informasjonsteknologi (IT) og operasjonsteknologi (OT) bør starte med tydelig use case og forretningsmål. Hos mange produksjonsbedrifter vil prosjekter ha fokus på vedlikehold av maskiner, optimalisering av prosesser eller produktanalyse for å forbedre kvalitet eller sporbarhet. Som en del av use case bør man identifisere prosjektomfanget og hvilke data som kreves. Det er viktig at alle tverrfaglige interessenter er involvert allerede fra prosjektstart, med felles prioriteringer og overensstemmelse over prosjektets mål.
Steg 2: Identifiser applikasjonen
Med use case og forretningsmål identifisert, er neste steg å identifisere applikasjonen som skal brukes for å nå disse målene. Still følgende spørsmål:
- Hvor er applikasjonen lokalisert: Nær datakilden (edge), i produksjonsområdet, i et datasenter, i skylagring eller annet sted?
- Hvordan kan applikasjonen motta data: MQTT, OPC UA, REST, database eller annet?
- Hvilken informasjon trenger applikasjonen?
- Hvor ofte skal data oppdateres, og hva skal forsake oppdateringen?
Dokumenter svarene før du beveger deg videre til neste steg.
Steg 3: Identifiser datakildene
Industridata er en viktig komponent for å adressere use case. Å få tak i industriell data og konvertere denne til nyttig informasjon kan være utfordrende. Derfor er det viktig å ha oversikt over tilgjengelig data.
Volum
En typisk, moderne industrifabrikk har hundre- til tusenvis av maskindeler og utstyr som kontinuerlig produserer data via PLS, maskinkontrollere eller distribuert kontrollsystem (DCS). Nyere automasjonssystemer kan også inkludere smartsensorer og smarte aktuatorer.
Korrelasjon
Automasjonsdata er primært for å håndtere, optimalisere og kontrollere prosessen. Denne dataen er relatert til prosesskontroll, og gjelder ikke vedlikehold, produktkvalitet eller sporbarhet.
Kontekst
Datastrukturen fra PLS og kontrollere har minimalt med beskrivende informasjon. Ofte er datapunktene referert til med kryptisk navngivning eller til adresselokasjonen i minnet.
Standardisering
Automatiseringen i en fabrikk utvikles over tid med maskiner og utstyr fra ulike leverandører av hardware. Dette er hardware som sannsynligvis er programmert og definert av leverandøren. Som resultat ser man unike datamodeller laget for hver enkelt maskin, med mangel på en felles standard for fabrikk og organisasjon.
For å kunne forstå de spesifikke utfordringene bør datakildene dokumenteres. Deretter kan du stille følgende spørsmål for å beskrive hvilken tilgjengelig data du trenger for å nå prosjektmålene:
- Hvilken industriell data er tilgjengelig?
- Hvor er dataen lokalisert: PLS, kontroller, database eller annet sted?
- Er det sanntidsdata eller metadata?
- Er dataen tilgjengelig i riktig format, eller er det behov for databehandling?
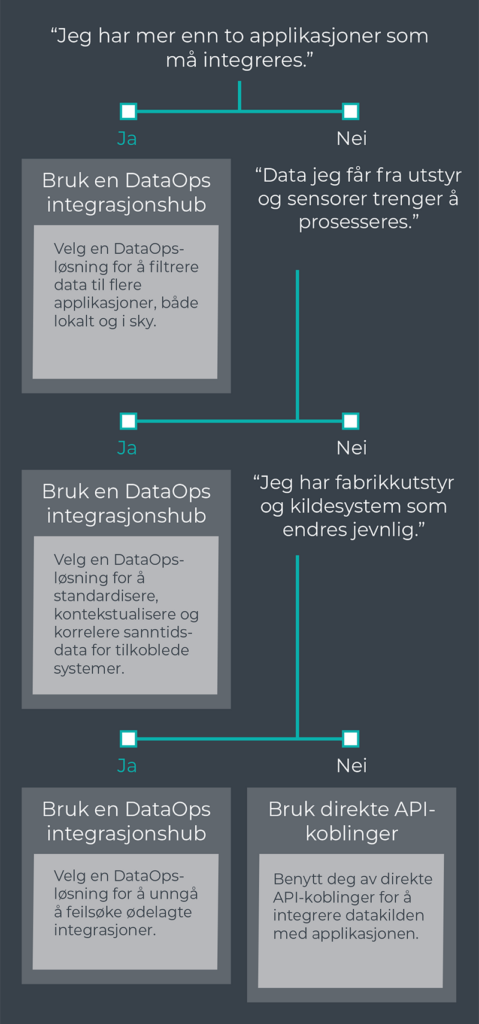
Steg 4: Velg integrasjonsarkitektur
Integrasjonsarkitektur er enten direkte API-tilkoblinger (applikasjon-til-applikasjon) eller integrasjonshuber (DataOps-løsninger).
Kobling med API fungerer godt hvis det kun er to applikasjoner som skal integreres. Dataen trenger ikke å prosesseres for den mottagende applikasjonen, og kildesystemene er statiske. Dette fungerer best der kun én SCADA- eller MES-løsning har all informasjon, og det ikke er andre applikasjoner med behov for tilgang til data.
Direkte API-koblinger fungerer dårlig når det er behov for å hente industridata gjennom ulike applikasjoner, som SCADA, MES, ERP, IIot Platform, Analytics, QMS, AMS, sikkerhetssystemer, ulike databaser, dashboard eller regnearkapplikasjoner. Det samme gjelder hvis det blir mange datatransformasjoner før overføring. Disse transformasjonene kan enkelt gjøres i Python, C# eller andre programmeringsspråk, men det innebærer at transformasjonene blir «usynlige», og vanskelig å vedlikeholde. API-koblinger møter også på utfordringer hvis datastrukturen endres jevnlig. Dette kan skje når fabrikkutstyr skiftes ut, eller det gjøres endringer i programmet som kjører utstyret. Vanlige årsaker til bytte av utstyr eller program kan være:
- Produsenten har små partier, som krever at man må laste nye programmer inn på PLS-ene.
- Produktene endres, og krever med det en endring i automatiseringen.
- Automasjonen endres for å øke produktivitet.
- Utstyr skiftes ut som følge av alder og ytelse.
Ved bruk av API skjules integrasjonen i koden. Interessentene kan være uvitende om endringer som gjøres i integrasjonen, som kan føre til at man ikke oppdager feil eller manglende data før etter flere uker eller måneder.
Et alternativ til direkte API-koblinger er DataOps Integration Hub. DataOps er en ny tilnærming til dataintegrasjon og sikkerhet, som sikter på å forbedre datakvaliteten og redusere tiden det tar å prosessere data før bruk i organisasjonen. En integrasjonshub fungerer som et abstraksjonslag, og gir alle applikasjoner tilgang til administrasjons-, dokumentasjons- og styringsverktøy.
Integrasjonshuben er spesialbygd for å flytte store datamengder i høy hastighet, med transformasjoner som utføres i sanntid, mens dataen er i bevegelse. Som en applikasjon, fungerer DataOps Integration Hub som en plattform for å identifisere innvirkningen fra utstyr og andre applikasjoner som endres, samt utføre synlige datatransformasjoner.
Steg 5: Opprett sikre tilkoblinger
Med prosjektplanen på plass, begynner systemintegrasjonen ved å sette opp sikre kilder og målsystem. Det er viktig å forstå protokollene det arbeides med, og hvilke sikkerhetsrisikoer og fordeler de gir.
Mange systemer støtter åpne protokoller for å definere kontaktpunkter og kommunikasjon. Typiske åpne protokoller inkluderer blant annet OPC UA, MQTT, REST, ODBC og AMQP. Det finnes også mange lukkede protokoller og API-systemer som defineres av applikasjonsleverandøren. Still følgende spørsmål:
Støtter protokollen sikre forbindelser, og hvordan opprettes disse forbindelsene?
Noen protokoller og systemer støtter sertifikater som utveksles mellom applikasjonene. Andre protokoller støtter brukernavn og passord, eller tokens som skrives manuelt inn i tilkoblingssystemet, eller gjennom en tredjepartsvalidering. I tillegg til brukersikkerhet støtter noen protokoller krypterte datapakker, som forhindrer dataen å bli lest i et innsideangrep. Til slutt finnes det protokoller som støtter dataautentisering. Dette innebærer at selv om dataen skulle blitt sett av en tredjepart, vil den ikke kunne endres.
Sikkerhet handler ikke bare om brukernavn, passord, kryptering og autentisering, men også om integrasjonsarkitektur. Protokoller som MQTT krever kun utgående åpninger i brannmurer, og forhindrer hackere i å komme inn på interne nettverk. Denne type protokoller er foretrukket av sikkerhetsansvarlige.
Steg 6: Modellere data
Distribusjonen av analyse eller IloT forsinkes ofte av variasjonen i data som kommer fra fabrikkanlegget. Maskinleverandører, systemintegratorer og produsenter har ikke fokusert på å lage datastandarder, men heller utvikle systemer over tid og tilpasse deretter. Som resultat kan hver maskin ha ulike datamodeller. Denne tilnærmingen har fungert for engangsprosjekter, men dagens IloT-prosjekter krever mer skalerbarhet.

Det første trinnet i å modellere data er å definere standardmodeller i målsystemet for å kunne oppfylle prosjektets forretningsmål. Kjernen i modellen er sanntidsdata som kommer fra maskiner og automatiseringsutstyr. De fleste sanntidsdatapunktene vil komme fra en enkelt datakilde. Når et spesifikt datapunkt ikke eksisterer, kan andre datapunkter benyttes ved hjelp av logikk. Data kan også analyseres eller hentes fra andre datafelt. Eventuelt kan det legges til ekstra sensorer som sørger for nødvendige data.
Disse modellene bør inneholde attributter for beskrivende data, som vanligvis ikke er lagret i industrielle enheter, men er nyttige når man matcher og evaluerer data i målsystemene. Beskrivende data kan være lokasjon, serienummer, måleenhet, operatørområde eller annen kontekstuell informasjon. Når standardmodellene er laget, bør de tilegnes hver maskin, prosess eller industrielt utstyr. Dette er vanligvis en manuell oppgave, men kan akselereres hvis det er konsistens fra enhet til enhet, og kartleggingen allerede eksisterer i Excel eller annet format, eller hvis en læringsalgoritme kan benyttes.
Steg 7: Dataflyt
Når modelleringen er fullført bør datastrømmene kontrolleres modell for modell. Dette utføres vanligvis ved å identifisere modellen, målsystemet og frekvens eller trigger for bevegelsen. Over tid vil dataoverføringene kreve overvåkning og styring.
Sammendrag
Fabrikker og andre industrielle miljøer endres over tid. Utstyr byttes ut, programmer endres, produkter redesignes, systemer oppgraderes og nye brukere trenger ny informasjon for å utføre jobben sin. Midt i denne endringen vil OT- og IT-fagfolk samarbeide om nye prosjekter som tar sikte på å forbedre produktivitet, effektivitet og sikkerhet. Det vil være nødvendig med industriell data som er standardisert og kontekstualisert. Det er nødvendig med et verktøy for å utføre denne oppgaven i stor skala, – som en DataOps-løsning. Ved å bruke en integreringshub kan man samle data fra forskjellig utstyr på et sted, for å så standardisere og kontekstualisere.








